本节内容
第二部分:关系代数与 SQL
对应教材:
- Chapter 2: Relational Model
- Chapter 3: Introduction to SQL
- Chapter 4: Intermediate SQL
- Chapter 5: Advanced SQL
- Chapter 6: Fromal Relational Query Languages
关系模型
数据模型 -> 关系模型
- 数据结构 -> 关系
- 数据操作 -> 关系代数
- 完整性约束条件:
- 实体完整性
- 参照完整性
- 用户定义完整性
关系数据库的结构
关系数据库由表的集合构成,每个表有唯一的名字。
- 关系 —— 表
- 元组 —— 表中的行
- 属性 —— 表中的列
关系
关系:给定集合 D1, D2, ……, Dn,它们的笛卡尔积为:
a 的关系 r 为笛卡尔积 D1×D2×⋯×Dn 的子集。
即 a 的关系 r 为元组 (a1,a2,⋯,an), ai ∈ Di 的集合。
- 元组:一组值的序列。
- 每一属性都有值域(允许取值的集合)。属性是原子的,即不可再分。
- 空值 null :表示值未知或不存在。
数据库模式
模式(schema):假设 A1, A2, ……, An 为属性,称 R = (A1, A2, ……, An) 为关系模式。
关系 r(R) 是指定义在关系模式 R 上的关系 r。
实例(instance):给定时刻数据库中数据的快照。
键(码,Key)
- 超键 (Super Key):能唯一标识一个元组的一个或多个属性的集合。
- 候选键(Candidate Key):【最小的超键】K 是候选键当且仅当 K 是超键且 K 的任意子集不是超键。
- 主键(Primary Key):被数据库设计者选中的,用来在一个关系中区分不同元组的候选键。
主键应该选择值不发生变化或变化极少的属性,且存储空间相对较小。
一个关系中只能有一个主键,但可以有多个候选键。 - 外键(Foreign Key):一个关系模式 r1 在属性中包括另一关系模式 r2 的主键,则这个属性在 r1 上称作参照 r2 的主键。
关系 r1 也称外键依赖的参照关系,r2 称为被参照关系。
SQL
- SQL:结构化查询语言
- 理论基础:关系代数+关系运算
- 组成:
- DDL 数据定义语言
- DML 数据查询语言
- 视图定义
- 完整性约束
- 事务控制
- 授权
- 嵌入式 SQL 与动态 SQL
SQL 数据定义语言
数据类型
- character / char(n) 固定长度为 n 的字符串
- character varying / varchar(n) 最大长度为 n 的可变长度字符串
- int / integer 整数
- smallint 小整数
- numeric(p, d) 定点数(精确数字)p 位数字,d 位小数
- real / double precision 浮点数 / 双精度浮点数(机器相关)
- float(n) 精度至少为 n 的浮点数
- date 日期
- time 一天中的时间 time(p):秒后小数点的数字位数(默认为0)
- timestamp date + time timestamp(p):秒后小数点的数字位数(默认为6)
- case e as t 将 e 转换为 t 类型
- extract (field from d):提取单独的域
- interval (数据类型):在日期、时间、时间间隔上进行运算
- blob 二进制大对象数据类型
- clob 大对象数据类型
- 当查询返回大对象时,返回“指针”
模式定义
1 | CREATE TABLE r ( |
默认值:DEFAULT 默认值
模式删除
删除整个表中的所有数据以及表的结构。
1 | DROP TABLE r; |
修改模式
1 | ALTER TABLE r <其他操作>; |
SQL 中数据库的定义与删除
创建数据库
1 | CREATE DATABASE db-name; |
删除数据库
1 | DROP DATABASE db-name; |
关系代数运算 & 对应 SQL 语句
选择
逐行判断是否满足条件 P。
1 | SELECT * FROM r WHERE P; |
投影
选定 A1,A2,⋯,Ak 列,并去除重复的行。
1 | SELECT A1,A2,⋯,Ak FROM r; |
广义投影
其中 F1, F2, …, Fk 为算数表达式。
关系运算的组合
前提:关系运算的结果仍然是关系。
1 | SELECT A1,A2,⋯,Ak FROM r WHERE P; |
SQL 注意事项
- 大小写不敏感
- SQL 语句默认不去重,即为
SELECT ALL,其中关键字 ALL 可以省略;而关系代数运算结果去重
SQL 结果如需去重,使用 DISTINCT 关键字:SELECT DISTINCT - 对于条件 P ,在 SQL 中可以使用任意的表达式以及 AND OR NOT 连接
判断在 N1~N2 范围内可以使用BETWEEN N1 AND N2
并 union
相容
并、交、差运算要求 r 和 s 是相容的:
- r 和 s 的元素要相同(同元),即属性相同
- r 和 s 的域要相容
1 | (SELECT * FROM r) UNION (SELECT * FROM s); |
差 set-difference
1 | (SELECT * FROM r) EXCEPT (SELECT * FROM s); |
交 intersection
1 | (SELECT * FROM r) INTERSECT (SELECT * FROM s); |
SQL 中的集合运算
- UNION,EXCEPT,INTERSECT 自动去除重复
如果不需要去重,使用 ALL 关键字:UNION ALL,EXCEPT ALL,INTERSECT ALL - 一个元组,在 r 中出现 m 次,s 中出现 n 次:
r UNION ALL s:该元组出现 m+n 次r INTERSECT ALL s:该元组出现 min(m, n) 次r EXCEPT ALL s:该元组出现 max(0, m-n) 次
笛卡尔积
若列名相同则重命名:表名.列名
1 | SELECT * FROM r,s; |
重命名
将表达式 E 重命名为 X:
SQL 语句 SELECT-FROM-WHERE 中的 AS 子句可以为属性、关系重命名:
1 | old_name | attribute_name | table_name AS new_name |
重命名应用
找到 S 表中属性 A 的最大值:
自然连接
r ⋈ s 是一个在模式 R∪S 上的关系,且满足:对于 r 中的每一个元组 Tr 和 s 中的每一个元组 Ts,Tr 和 Ts 有相同的属性,且它们的取值相同。(即同名属性值相同)
对于模式:
定义:
1 | SELECT r.A, r.B, r.C, r.D, s.E |
外连接
外连接是连接运算的扩展,可以避免信息的丢失(自然连接:无法连接时会丢掉数据)。
| 解释 | 图示 | SQL |
|---|---|---|
| 内连接 | 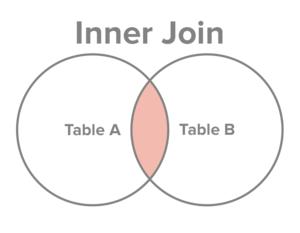 |
A INNER JOIN B INNER 可以省略 |
左外连接:左表全部出现在结果集中,若右表无对应记录,则相应字段为NULL |
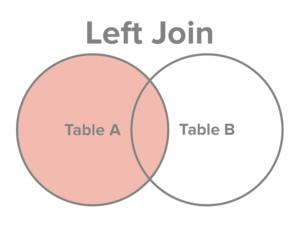 |
A LEFT OUTER JOIN B OUTER 可省略 |
右外连接:右表全部出现在结果集中,若左表无对应记录,则相应字段为NULL |
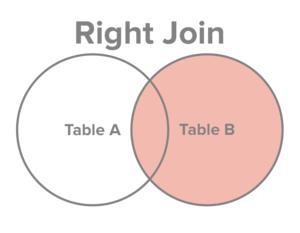 |
A RIGHT OUTER JOIN B OUTER 可省略 |
| 全外连接 = 左外连接 + 右外连接 | 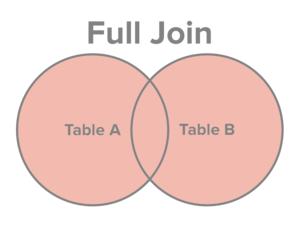 |
A FULL OUTER JOIN B OUTER 可省略 |
连接条件
- NATURAL 自然连接
A INNER JOIN B ON A.attr = B.attr等价于A NATURAL JOIN B - ON P 指定连接条件
- USING (A1, A2, …, An) 指定连接属性
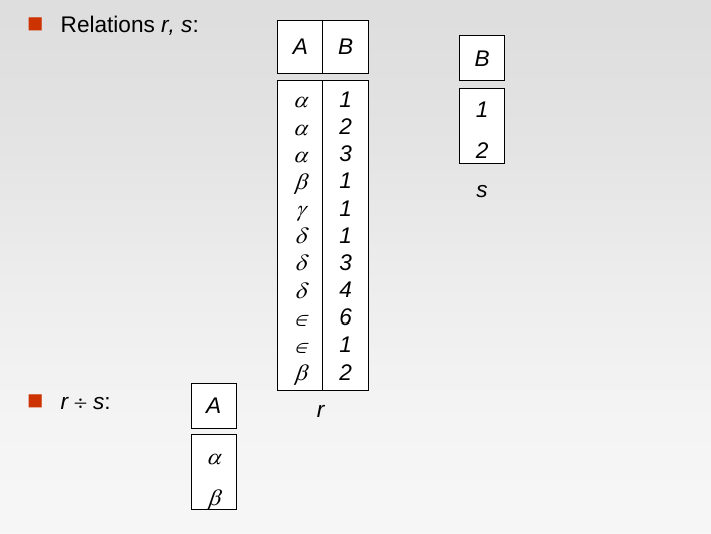
☆ 除
给定模式:
设 r 是模式 R 上的关系, s 是模式 S 上的关系,r÷s 是模式 R-S 上的关系,且有
定义:
- 为候选结果
- 为候选结果中不存在的那部分
- 为所有可能的结果
- 为实际选择的结果
聚集
聚集函数:AVG MIN MAX SUM COUNT
除 COUNT 外,聚集函数均忽略空值 NULL。
COUNT(*):统计元组(行)的个数,不去除重复(如需去重使用 DISTINCT 关键字,COUNT(DISTINCT attribute-name))
定义:
- Gi 为用于分组的一系列属性;
- 每个 Fi 为一个聚集函数;
- Ai 为属性名。
1 | SELECT F1(A1),F2(A2),⋯ ,Fm(Am) |
- 如果不给出分组属性,默认将整个关系作为一个分组
- Ai 必须出现在 Gi 当中,即没有出现在 GROUP BY 子句中的属性不能在 SELECT 子句中使用
- WHRER 子句是对行进行选择;如需对各个分组进行选择需要使用 HAVING 子句:
HAVING P谓词 P 对 GROUP BY 子句中各属性构成的分组起作用,可以使用聚集函数 - 对于聚集函数得到的结果可以使用 AS 子句重命名
赋值
将结果赋值给变量,便于复杂计算。
SQL 中附加的基本运算
字符串通配符
%匹配任意子串(长度任意)_匹配任意单个字符(1个字符)
使用:LIKE "模式字符串" 或 搜索不匹配项 NOT LIKE "模式字符串"
指定转义字符:ESCAPE '\'
结果排序
1 | ORDER BY <attributes>; |
默认升序排列(ASC),使用 DESC 表示降序排列。
空值
- 含义:值不存在或不知道。
- 任何算数表达式中,若包含 null 结果一定为 null ;通常聚集函数求值会忽略 null。
- 在 SQL 中,认为 null 是相等的,判断是否为空需要使用
IS NULL。 - 空值参与比较运算,结果返回 unknown :
unknown = not unkonwn;P is unknown = true if P = unknown
数据库的修改
删除
其中 r 为关系,E 为一些元组的集合。
删除的单位是一行。
1 | DELETE FROM r |
- WHERE 子句可以为空:删除整张表中所有的元组(但不删除表的结构)
插入
单位为一行(也可以同时插入多条数据)。
1 | INSERT INTO r [(属性名...)] |
若不给出属性名,则按照表的属性数量和顺序一一对应插入;否则数据与属性名对应。
1 | INSERT INTO r [(属性名)] |
将查询结果批量插入表中。
更新
更新最小单位为一个属性值。
1 | UPDATE r |
其中数值可以使用 CASE 语句:
1 | CASE |
SQL 嵌套查询
集合成员资格判断
IN / NOT IN => TRUE / FALSE
IN:测试元组是否是集合中的成员,也可用于枚举集合
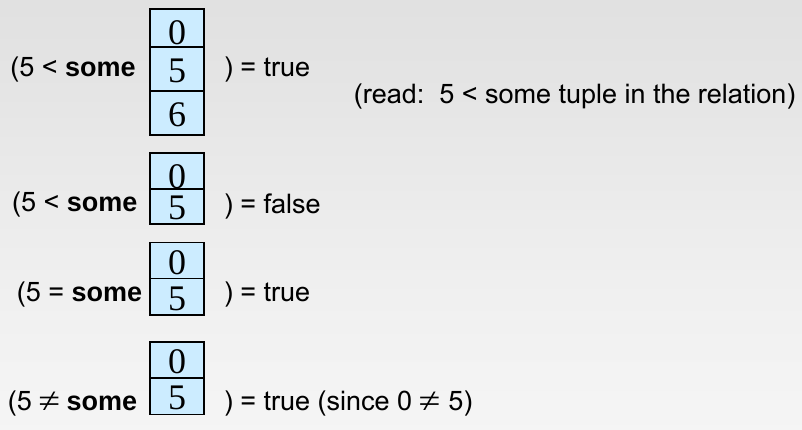
集合的比较
- SOME 至少有一个满足
- ALL 对于所有都满足
其中,<comp> 可以为 <、<=、>、>=、=、<> 。
= SOME等价于IN,但是<> SOME不等价于NOT IN<> ALL等价于NOT IN,但是= ALL不等价于IN

空关系测试
判断集合中是否包含元组。
例题:实现除法
Find all customers who have an account at all branches located in Brooklyn.
1 | select distinct S.customer_name |
注意到:
重复元组存在性测试
UNIQUE 测试一个集合中是否存在重复元组。
视图
视图:虚拟的表、不存储数据(而是基于原始表中的数据),隐藏部分数据。
1 | CREATE VIEW view-name AS |
存储:不存储数据,只存储定义(在数据字典中),可以来源于一张或多张表。
视图的更新
- 当使用 INSERT、UPDATE、DELETE 来对视图数据进行更新时,将会转换为基表的更新动作。
- 一些复杂的视图(如视图中某些列为聚集结果)。由于操作无法转换到基表,故更删改无法成功。
衍生关系
在查询的结果上进行查询,相当于构造一个临时的视图并进行查询。
1 | <select-from-where> |
with 子句
使用
CREATE VIEW创建的视图是永久性的。
使用 with 子句可以创建一个临时的视图。
1 | WITH name (attributes...) AS |
事务
事务:数据库应用中完成单一逻辑功能的操作集合。由查询/更新语句的序列构成。
一条 SQL 语句执行,隐式地开始一个事务。
- COMMIT WORK 提交当前事务 -> 持久保存
- ROLLBACK WORK 回滚当前事务 -> 撤销
构成单一事务:
1 | BEGIN ATOMIC |
完整性约束
作用:保证数据的正确性和统一性。
实体完整性
- NOT NULL 不允许为空值
- UNIQUE 取值唯一
- CHECK(P) 满足 P 条件
参照完整性
参照完整性:一个关系中给定属性集的取值也在另一关系的特定属性集的取值中出现。
- 主键约束:PRIMARY KEY 属性
- 外键约束:FOREIGN KEY 属性 REFERENCES 对应关系
当参照表数据变化时
级联:
- 修改:FOREIGN KEY 属性 REFERENCES 对应关系
ON UPDATE CASCADE - 删除:FOREIGN KEY 属性 REFERENCES 对应关系
ON DELETE CASCADE
置空/默认值 (以删除为例):
- 置空:FOREIGN KEY 属性 REFERENCES 对应关系
ON DELETE SET NULL - 使用默认值:FOREIGN KEY 属性 REFERENCES 对应关系
ON DELETE SET DEFAULT
断言
相关数据变化时都会检查,影响性能。
1 | CREATE ASSERTION name |
授权
授权
1 | GRANT <权限列表> |
收回
1 | REVOKE <权限列表> |
默认级联收回(关键字 CASCADE,可省略),可以申明 RESTRICT 防止级联收回(存在级联收回权限会返回错误)。
权限的转移
SQL 默认不允许被授予权限的用户/角色将权限授予他人,如果需要,在相应的 GRANT 命令后添加:
1 | WITH GRANT OPTION; |
权限列表
- 对数据的授权(可后接属性名)
- SELECT
- UPDATE
- INSERT
- DELETE
- 对模式的授权:创建、修改、删除
嵌入式 SQL
- 将 SQL 嵌入到高级程序语言(称为宿主语言)中。
- 预处理 主语言 + SQL => 主语言 + 函数调用
ODBC JDBC
- ODBC(开放数据库互联):定义一组 API ,使应用程序可以使用相同的 ODBC API 来访问数据库。
- JDBC:Java 数据库连接
About this Post
This post is written by Holger, licensed under CC BY-NC 4.0.